New CI Hands-on tutorial: Efficient Continuous Integration for large scale C++ projects with Conan 2




We are very excited to present a completely new Conan tutorial, focused on Continuous Integration for large C++ projects. Documentation, examples and best practices have been demanded for a long time, and even if there was some previous material, it is the first time that Conan introduces a tutorial like this specific for CI.
The new CI tutorial builds on top of lots of experience and feedback from users gathered over the last years. This feedback was already incorporated in the design of Conan 2 in the form of new tools and best practices, but a dedicated documentation entry point was missing.
In this blog post, we’ll take a brief tour of the most important concepts covered in the tutorial to provide a general overview of the problem. While the tutorial offers detailed, step-by-step instructions, hands-on exercises and in-depth explanations, this post aims to highlight the key points and give you a broad understanding of the subject.
Tutorial overview
The tutorial is a hands-on one. It uses the source code in the “examples2” Github repository to have something that users can fully reproduce, in any platform, command by command. It is intended to be done this way, and sections in the tutorial are incremental and related, it is necessary to do them in sequential order.
The tutorial is not using a specific CI system, and the different packages are not yet in separate and independent Github repositories, but inside folders emulating them, for convenience. The idea is to focus on the best practices, flows and Conan tools, to understand them, and how they can be used to implement such CI in a real system.
These tools are introduced with a specific example: given an organization with some different products that depend on several different packages, how a change in a package that creates a new version of it can be tested, validated and integrated in the organization products in an efficient way.
Consequently, the tutorial doesn’t aim to be a silver bullet, or to be adopted as-is for all possible different flows, release processes, branching and merging strategies of an organization. This will be the subject of future work, when the tutorial will be extended with more examples and use cases.
Practical Example
The tutorial uses the following project, that includes 2 main “products” that an organization is developing: a “game” application and a “mapviewer” tool. These main products depend on different packages that contain libraries implementing different functionalities:
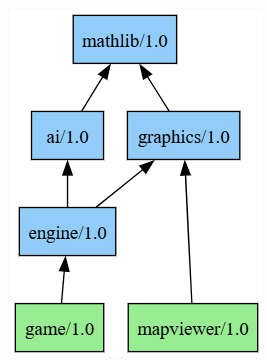
In this project, the tutorial simulates a developer doing a change to the ai/1.0 package, changing the source code, and releasing a new ai/1.1 version. The Continuous Integration process has two parts:
- A “packages pipeline” that builds the new
ai/1.1package, to ensure that the developer changes are locally (within theaipackage) correct, but that do not care about the consumers. - A “products pipeline” that builds the organization main “products”
game/1.0andmapviewer/1.0, integrating the newai/1.1version, to check that it integrates cleanly, and re-building any necessary intermediate packages, in this example,engine/1.0might need a re-build from source too.
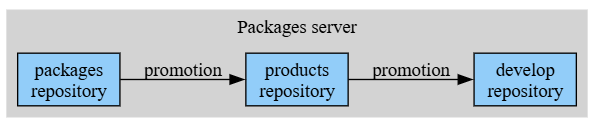
In this project CI, the tutorial uses 3 different server package repositories: “packages”, “products” and “develop”. Developers mainly use the “develop” repository while working, it is assumed to be relatively stable, similar to a “develop” branch in a Git repository. In the same way that a “develop” branch only accepts changes from a Pull Request that have previously been approved by running tests in CI, the “develop” package repository will only accept packages that have been previously validated.
The “packages” and “products” repositories are intended to host packages built by CI before they are approved. For example, a “packages pipeline” can create and upload to “packages” the new ai/1.1 binaries. But that doesn’t mean that these packages won’t break the “develop” repository, until a “products” pipeline builds the full products in the “products” repository, these packages won’t be promoted to the “develop” repository.
Promotions are the mechanism to copy packages from one server repository to another, making them available to different parts of the CI process and to different consumers (developers and/or other CI jobs)
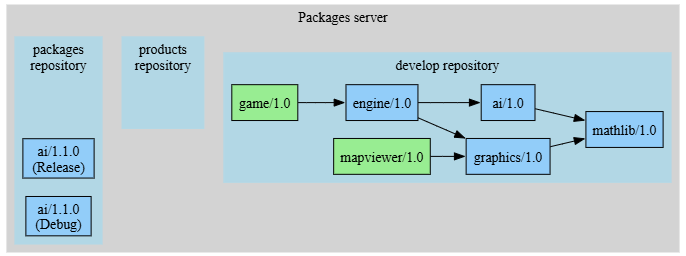
The packages pipeline
Imagine a developer doing some changes in the ai package, changing the source code and updating the recipe to produce a new ai/1.1 version.
The package pipeline builds this new version for multiple different configurations (for this example we use Release and Debug configurations for easier reproduction, but in real scenarios it could be Windows and Linux), uploading those configurations to the “package” repository. This way, only if all the different configurations are built correctly can the changes be considered valid. While the “packages pipeline” is running the new binaries will be uploaded to the “packages” repository:
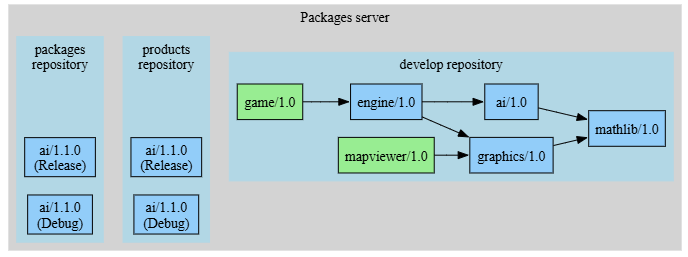
And when the different configurations are built correctly, they can be “promoted”, that is, copied from the “packages” repository to the “products” repository, to make them available to the following “products pipeline”:
One important aspect of the pipeline is consistency and traceability. If the different configurations are built in different computers, like different Windows and Linux build agents, the builds can happen at different times. If there are other concurrent processes in CI, and for example some other job uploads a new mathlib/1.1 version, it could be possible that the ai/1.1 binary for the Windows configuration is built with mathlib/1.0 and the ai/1.1 binary for the Linux configurations is built with the newer mathlib/1.1. To avoid this, Conan lockfiles can be used to guarantee the same set of dependencies everywhere and in different time steps, even if new versions of dependencies are later uploaded. Lockfiles provide reproducibility of dependencies.
The products pipeline
This is the part of the pipeline that takes packages in the “products” repository, that successfully passed the “packages pipeline” and tries to integrate them into the organization’s main products.
There are 2 important commands used in a “products pipeline”:
- The
conan graph build-ordercommand computes what packages and in what order needs to be built, for a given product and a given configuration. - The
conan graph build-order-mergeallows to compute a single build-order file from multiple products and configurations, to avoid duplicated builds of the same packages.
The graph build-order files can be represented as html with the --format=html output, in our example it would be something like:

And it means that with the given new ai/1.1 version, only the engine/1.0 and the game/1.0 need to build new binaries, and in that specific order.
The build-order files also provide the necessary information of what packages can be built in parallel at every stage, for a faster CI.
Following the results of the build-order, it is possible to re-build from source the necessary packages in the CI agents. If everything builds correctly then the “products pipeline” can consider that the new ai/1.1 package version integrates cleanly and run a promotion, copying the packages built in the products pipeline that were stored in the “products” repository, to the “develop” repository, making them finally available to other developers and CI jobs.
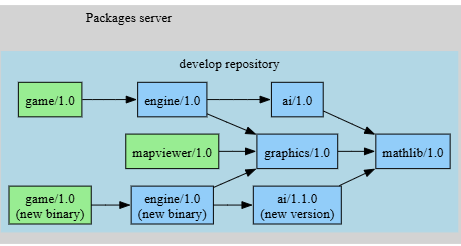
Note that the Conan binary model is not breaking the previous release. The game/1.0 package now contains 2 different binaries, one binary built against the previous ai/1.0 version, that can still be used, tested, deployed to customers, etc, and a new binary built against the new ai/1.1 binary that will incorporate the latest changes from that package.
It is also important to note that game didn’t change its version. This is still a development stage, and the game/1.0 package ties its version to its source code. The source code of game/1.0 package didn’t change at all, so it didn’t have to bump the version. The version of the game/1.0 package wouldn’t be necessarily correlated to the final release of the whole product; that could get a different release name and versioning scheme.
Conclusions and future work
This blog post isn’t a full explanation of the CI, it is just a peek preview of its contents. The full CI tutorial with all the detailed explanations, exercises, and code is already live at CI Tutorial section in the Conan docs, go and try it! As always, feedback is very welcome, if there are any questions or issues with the tutorial, please let us know opening a ticket in the Conan Github repository
Recall that the tutorial doesn’t aim to be a silver bullet or the only possible way to implement CI, but mostly an overview of principles, best practices and tools that Conan provides to implement CI at scale for C++ projects.
Finally take into account that this is only the first planned part of the full CI tutorial story. There are still many use cases, alternatives scenarios, possible implementation details, different branching, merging and integration strategies, etc. that were not covered yet by the tutorial. Keep tuned for the new release, and don’t hesitate to use the the Conan Github repository for feedback about possible future improvements.