DevOps and Continuous Integration challenges in C/C++ projects




Modern SW development and engineering has evolved in the last decade. Agile SW development, Continuous Integration (CI), Continuous Deployment or Delivery (CD) have become mainstream practices. Specialized roles decay while full stack engineers are on the rise. Coding, building & testing, releasing, deploying and monitoring have become more tightly connected than ever due to the need to produce more releases, faster, under a common discipline: DevOps.
DevOps’ goal is to improve the SW processes, time to market, rate of failures, release times, and reduce the time from when an error is reported until it is finally deployed with a successfully validated fix. Many top tech companies are able to continuously deploy hundreds of times per day to their production systems. Such responsiveness is becoming a necessity: release fast or die!
C and C++ projects are the backbone of not only SW, but also the whole IT industry: from Operating Systems, embedded systems, finances, research, automotive, robotics, gaming, and more. The increasing speed of technology, business and science is demanding to accelerate their processes. C and C++ projects must embrace the modern DevOps culture.
However, there are quite a few challenges to face. The first is the huge project size compared to other languages. After reading an article about a JavaScript codebase calling itself huge for a few tenths of thousands lines of code, I ran a (statistically insignificant) survey for C and C++. A C or C++ project is considered to be large from 10 Million lines of code. Compilation times for such projects can be several orders of magnitude larger than those of other languages.
Being a language that is compiled to native machine code, Application Binary Interface (ABI) incompatibility is also a big problem. Other languages, even when compiled to bytecode, don’t suffer from this challenge. What about Rust and Go, two modern languages that compile to native code? Well, they also don’t really suffer from ABI incompatibility. For example, their respective package manager, “Cargo” and “goget” (there are other alternatives), mostly build their dependencies from sources together with the app, to generate the resulting binary. They might even enforce the linkage of the application, using static linkage for simplicity.
Rust and Go can afford this approach, since projects in these languages are several orders of magnitude smaller than those in C and C++, and distributing binaries (like proprietary components) for those languages is still not a common thing. But, as we said, C and C++ projects are huge, so managing binaries and dealing with ABI compatibility is absolutely necessary.
C and C++ building
First, let’s understand a bit about the C and C++ building process. For example, how source code is compiled into native code in static or shared libraries, how they are linked, how the preprocessor works, etc. Rather than just explaining it, let’s exemplify the issues with a simple scenario. Let’s build a “math2” library, implemented with the following files:
//math2.h
# pragma once
int add(int a, int b);
//math2.cpp
#include "math2.h"
int add(int a, int b){
return a + b;
}
Building it as a static library (in Ubuntu 16, gcc 5.4, CMake static library, Release mode), we get the following code (objdump -d libmath2.a):
0000000000000000 <_Z3addii>:
0: 8d 04 37 lea (%rdi,%rsi,1),%eax
3: c3 retq
We can see the add function of two integers addii, and the lea operation is nothing but a tricky (faster) addition.
Let’s now create another library for 3D operations, called “math3”, with the following source code:
//math3.h
# pragma once
int add3(int a, int b, int c);
//math3.cpp
#include "math3.h"
#include "math2.h"
int add3(int a, int b, int c){
return add(add(a, b), c);
}
Building it as a static library we get (objdump -d -x libmath3.a):
0000000000000000 <_Z4add3iii>:
0: 53 push %rbx
1: 89 d3 mov %edx,%ebx
3: e8 00 00 00 00 callq 8 <_Z4add3iii+0x8>
4: R_X86_64_PC32 _Z3addii-0x4
8: 89 de mov %ebx,%esi
a: 89 c7 mov %eax,%edi
c: 5b pop %rbx
d: e9 00 00 00 00 jmpq 12 <_Z4add3iii+0x12>
e: R_X86_64_PC32 _Z3addii-0x4
Let’s modify now the math2 add function, for example:
int add(int a, int b){
return a + b + 1;
}
We will get a different machine code for math2.lib:
0000000000000000 <_Z3addii>:
0: 8d 44 37 01 lea 0x1(%rdi,%rsi,1),%eax
4: c3 retq
But inspecting the math3.lib, we can see that it is exactly the same code, it has not changed at all!
But if we change the library type, and build a math3.so shared library instead, the machine code we will get would be:
0000000000000660 <_Z4add3iii>:
660: 53 push %rbx
661: 89 d3 mov %edx,%ebx
663: e8 d8 fe ff ff callq 540 <_Z3addii@plt>
668: 89 de mov %ebx,%esi
66a: 89 c7 mov %eax,%edi
66c: 5b pop %rbx
66d: e9 ce fe ff ff jmpq 540 <_Z3addii@plt>
672: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
679: 00 00 00
67c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000000680 <_Z3addii>:
680: 8d 44 37 01 lea 0x1(%rdi,%rsi,1),%eax
684: c3 retq
We can clearly see that the code for the math2.a static library has been “embedded” inside the shared library, so it basically contains a copy of the machine code existing in the math2.a static library. If the math2 library source code changes, and everything is rebuilt, the math3.so machine code will then be different.
This problem does not only apply to compiled code inside static libraries being linked into a shared library. The same problem happens with headers. If we change math2 to be a header only library, implemented in math2.h:
# pragma once
int add(int a, int b){
return a + b;
}
Then, building the static library math3.lib will lead to:
0000000000000000 <_Z3addii>:
… # irrelevant
0000000000000010 <_Z4add3iii>:
10: 8d 04 37 lea (%rdi,%rsi,1),%eax
13: 01 d0 add %edx,%eax
15: c3 retq
Headers are included by the preprocessor in the compilation units of the consumer, so the problem is that also in this case, the final machine code of math2 has been embedded/copied into the binary artifact of math3. Even if the add function has been embedded in the binary, the implementation of the add3 has effectively inlined the add function. In practice, the above code can easily break the “one definition rule”, so it is typical to find it explicitly inlined:
inline int add(int a, int b){
return a + b;
}
In any case, inlining is just a suggestion to the compiler, which can do it even if not declared, or could even ignore it. Also, inlining can be aggressively done by compilers at link time across binary artifacts boundaries with “Whole Program Optimization” or “Link-Time Code Generation”. But the problem is the same, any change done in the “math2” component, produces changes in the binaries of the “math3” component.
C/C++ build systems are able to cache compilation results and apply logic over the source code changes to efficiently perform incremental builds, skipping what is not necessary to be re-built. Unfortunately, these techniques apply for builds within the same project, so they cannot be easily applied if code is reused between different projects. Moreover, this approach is not enough for Continuous Integration.
Binary management in C/C++
What has been described in the previous section is just as important to DevOps working with C and C++. This is because a C/C++ compiled binary artifact can change despite the fact that its sources do not change at all.
This issue is not only related to code dependencies, but also widely related to system and development configuration. Native code is different in different OS’s, but also, different compilers will produce different binaries from the same source code. Even different compiler versions of the same compiler will generate different binaries from the same source code, as compiler technology evolves and is able to optimize code further and further. Also, different artifacts can be generated from the same source code, as we have seen above, we can build the same library as static or shared, and they will definitely result in different binary artifacts.
In some (extreme) cases, where the C/C++ projects are single platform, and the development tools are completely fixed and frozen within the organization,a one-to-one correspondence can be assumed between source code and compiled binaries. This is somewhat the case of Java with their “build once, run everywhere” mantra. But for languages with native code, this is not the case. For example, when python packages contained native extensions, it was difficult to manage them, requiring building from sources at install time (and requiring a compiler, which was an inconvenience for many python developers), or other difficult processes. Python-wheels (http://pythonwheels.com/) improved this issue by providing different binary packages with a naming convention for the same source package.
An efficient DevOps process, able to manage different binaries from the same source code, is required.
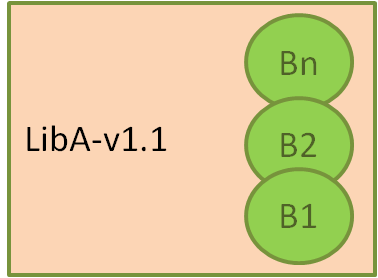
Here, we represent our system, in which we have one component or package, called LibA, with its source code in version 1.1. Several binaries have been built and stored, from the same source code, called B1…Bn. For example, for different OS’s, such as Windows, Linux, and OSX.
This would be a common pattern for any system. For example, the Conan C/C++ package manager uses recipes to build different binaries from the same source code, and all these binaries can be uploaded and stored together under the same reference in a conan remote server (conan_server or Artifactory).
The problem of Continuous Integration for C/C++
Both the need to reuse code between projects, but also the needs to tackle complexity and deal with the huge size of C/C++ projects, requires some “component-ization” or “packaging” of components. Well-known as the divide & conquer pattern.
The problem with such components, is that they no longer belong to the same project. In fact, they can (and often do) have different build systems, so caching compilation results for subsequent incremental builds is not possible. Furthermore, one of the established Continuous Integration best practices is building full builds in clean environments, from scratch, as much as possible, to ensure reproducibility and avoiding the “works in my machine” issue.
Let’s proceed with an example. Imagine we have the following components in our Jenkins Continuous Integration systems, mainly libraries and executables for simplicity, but components could also be groups of libraries or other artifacts or data. Let’s assume for the sake of simplicity, that for all these components the system built just one binary, for one platform:
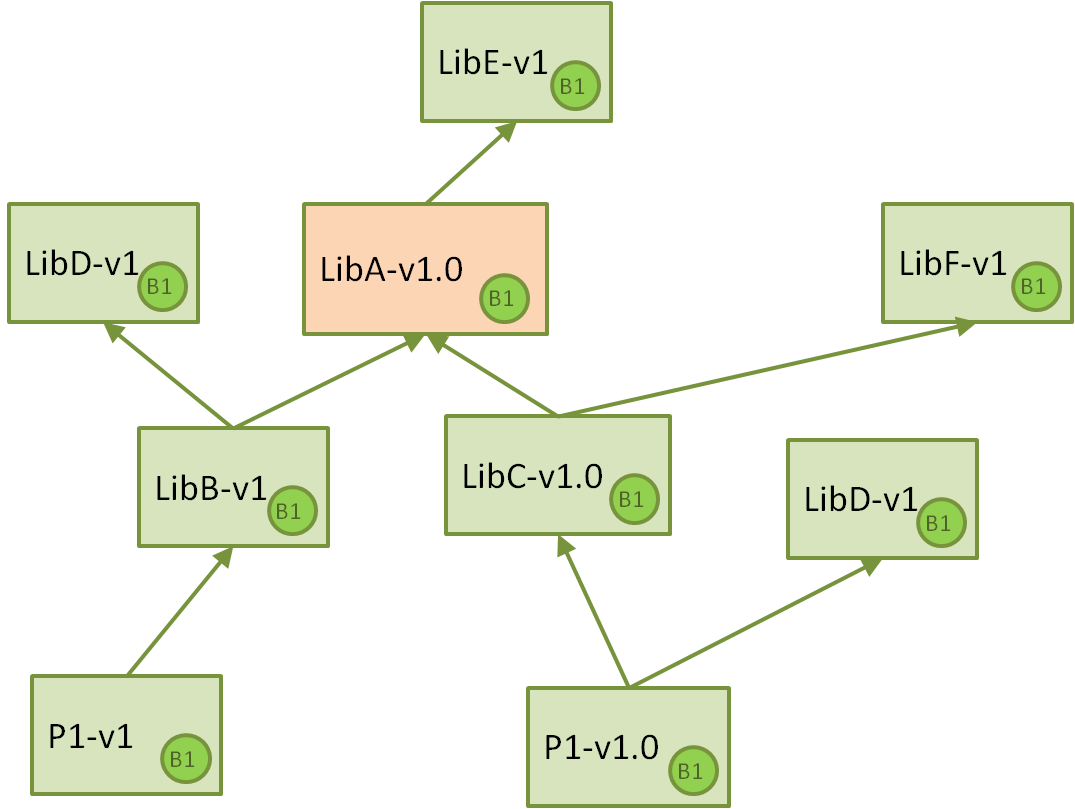
So we have two projects, each one builds a final application to be deployed somewhere. These projects depend on different libraries, specific versions, some of them can be shared between the projects, and others cannot.
Now, let’s suppose that some poor performance is detected in LibA, then a developer clones the repo for LibA, optimizes the code and increases performance, as it is not a major change, bumps the version to 1.1, and pushes the repo, so a CI job is fired and a new package for it is created:
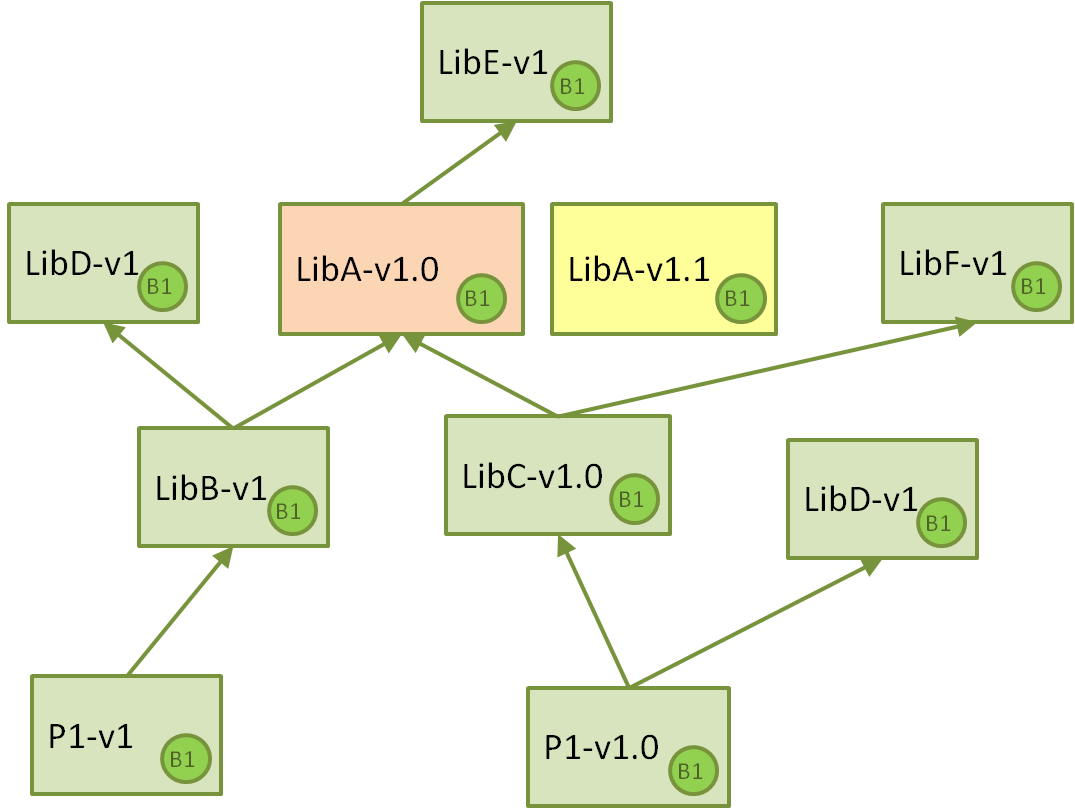
The Jenkins CI job for doing this task shouldn’t be a big problem. But now, the important thing is that we want the bug fix to be propagated downstream, and so finally new versions of the Project Apps are created. This is when the challenges begins.
The first question we have to answer is whether such a version should be automatically propagated downstream in CI. That would mean of course, triggering the build of dependent packages, in the adequate order. Overall, this sounds like a troublesome approach, that could easily lead to problems and unnecessary saturation of our CI servers.
First, let’s figure out a manual process. The team decides that LibC-v1.0 should now use the newest LibA-v1.1, so they clone the LibC repo, bump the dependency to LibA, increment their own version to LibC-v1.1 and push the changes, so a new package with a new binary is created by the Jenkins CI job.
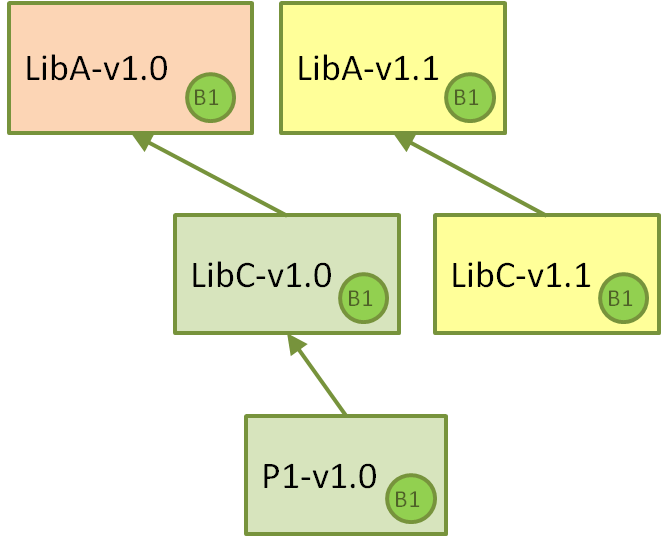
This indeed works, and could be done. It could make sense for versioning schemes including build metadata, but inconvenient for others. Then an important question appears:
“Why should the version of LibC be incremented? No real change has been done to the code at all. We just used a new version of the dependency. But as shown above, this may or may not change the resulting binary, so maybe it is not necessary to create a new package and build a new binary!”
That is true, an efficient package management and CI system should be able to cope with this scenario. Two things have to be defined for such a goal:
- Re-build logic: The ability to define some logic in
LibCwhether it needs to build a new binary or not when changes in its dependencies happen. - Dependency redefinition: The ability to create a new binary for
LibC, with a different dependency than the one which it was declared with.
Re-build logic: semver not to the rescue
At first sight, and from our experience from other languages, we could be tempted to say that the first question would be answered by Semantic Version (semver). However, remember the section above: even small, compatible changes done in the private implementation of a component, can imply changes in the binaries of its dependents.
The only possible strategy here is to let developers define it, which is the Conan C/C++ package manager approach. It allows to define a package_id() method that can specify the impact it has to its own binary for each dependency. Semantic versioning can be an option for static-static linkage without changes in the public headers, but for shared-static linkage, every change in the dependency binary will require building a new binary for it. It is possible to do this conditionally, enabling the package to build both shared and static binaries, with each one following their own re-build logic.
Dependencies redefinition
The manual process would be to manually increase the dependency version in the package. But, this will definitely change the current package, if it is hashed or versioned somewhere, and this change can have consequences. For example, a change in a package could fire CI jobs to rebuild that package.
The goal here is to be able to redefine the LibA-v1.0 version that LibC-v1.0 had, without modifying LibC at all. There are two strategies for this:
- Version ranges. Instead of having LibC declare a “hardwired” dependency to
LibA-v1.0, it could have declared a version range, and instead for example depend onLibA-v1.X. This approach can have constraints inconvenience, such as depending on a rangeLibA-v1.[0-3]and having a newLibA-v1.4we to depend on as well. - Version overriding. This is the same as Maven’s approach. You can declare the version you want to use downstream, and this specified version will override any other upstream declared versions.
The result with this approach would be one of the following:
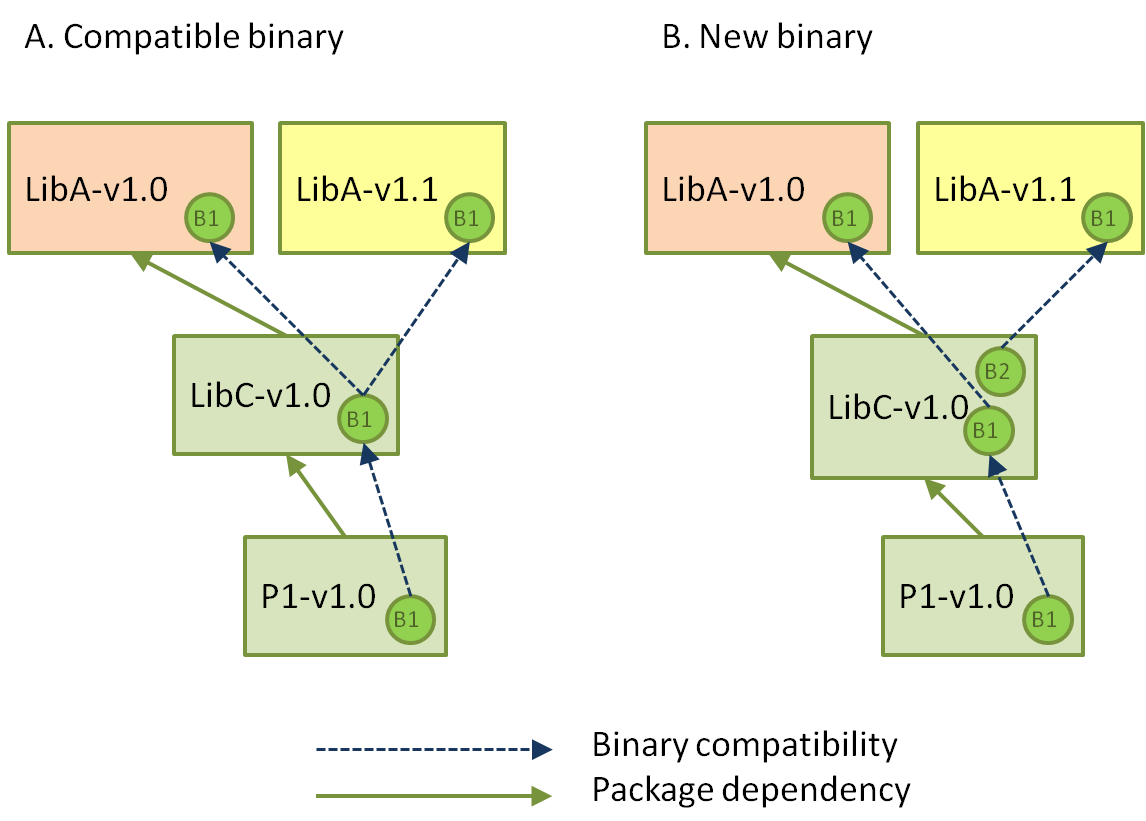
In scenario A, the LibC-v1.0 is compatible with both LibA-v1.[0, 1], and it’s unnecessary to built a new binary for it. This could be the case of a static library, and the minor version increase in LibA doesn’t imply changes in the public headers. In case B, it is necessary to create a new binary for LibC. This could be the case of LibA being a header only library, or LibC being a shared library.
Automating the propagation
This process could be repeated downstream, instructing the packages to build if necessary. But it is important to respect the graph ordering, otherwise, it is possible that some binaries will not be correctly built with the latest upstream versions.
This is where it would be interesting to setup a CI process to do this automatically. We already discarded the process of automatically upgrading everything downstream after a new version of LibA, so the process should be fired from downstream.
One process could be to define the overriding dependency to LibA-v1.1 directly in the consuming project, like P1, and let this dependency propagate upstream requiring every node in between to build a new compatible binary if necessary. For multi-configuration projects (multi-platform, or compiling with different settings) that would be like a depth-first approach, for every configuration (compiler, version, settings), the packages in the graph would be built.
However, we may want to properly build and test each package as needed, maybe for many configurations, before proceeding downstream. The first question that the package manager should tell the CI system, is what dependencies are involved. The question could be:
“Given that the LibA has been upgraded, what packages should be checked if a new binary is necessary for project P1 being also upgraded?”
And the answer should be an ordered list of [LibC-v1.0, P1-v1.0].
A chain (respecting the order) of CI jobs can be fired with this list, each one to build, if necessary, a new binary for each package. Each job could apply to each package dependency overriding, or have defined version ranges, as well as the re-build information.
Conclusion
There are many open challenges in DevOps, and specifically in Continuous Integration for C and C++ projects. The Conan Package Manager implements some of the necessary pieces in this puzzle:
- It can build and manage many different binaries for the same source code and same package recipe, hosting the binaries in a conan_server or in Artifactory.
- It can define the re-build logic through the
package_id()method, which is how the different configurations of the package and the dependencies that affect the binary can be defined. - It provides dependency management, with version overriding, conflict resolution and version ranges. This allows to propagate along package changes in dependencies without actually having to edit the package recipes, just generating different binaries for different dependencies.
- It provides information for the build order of dependencies (
conan info --build-ordercommand). This information can be queried for any package, which would be the order of packages to process when an upstream is changed.
However, these are only the pieces. We are working on improving these CI tools, and definitely need your feedback! Here are some of the questions we would love to hear back from you on:
- Would the manual approach make sense in your CI process? Would you prefer to generate new packages, bumping the dependencies in your recipes?
- If not, what would be your desired approach? Building binaries when necessary for whole projects, or building more on a per-package approach?
- Would you prefer using dependency overriding or version ranges?
Please provide us with any ideas, suggestions and feedback that you may have about your DevOps and CI in your C and C++ projects, and we will continue to provide the best possible tools for the C and C++ communities.