Supporting Different C/C++ Package Paradigms with conan




Some developers think that a package manager for C/C++ should, by default, bundle both debug and release artifacts in the same package, so that they can easily be used by developers changing configuration while working.
But other developers might think that this is not good practice, and that release and debug packages should be different and installed separately by default. Linux “-dbg” symbol packages is an example.
The truth is that both have advantages and disadvantages, and if we have learned something from our experience in developing package managers it’s that there is no absolute truth, and a C/C++ package manager should provide the means for developers to support the packaging paradigm they want to implement. We constantly listen to users feedback, and the latest Conan 0.20 release contains some utilities that help support multiple package paradigms.
First, it is interesting to review and understand how Conan processes packages:
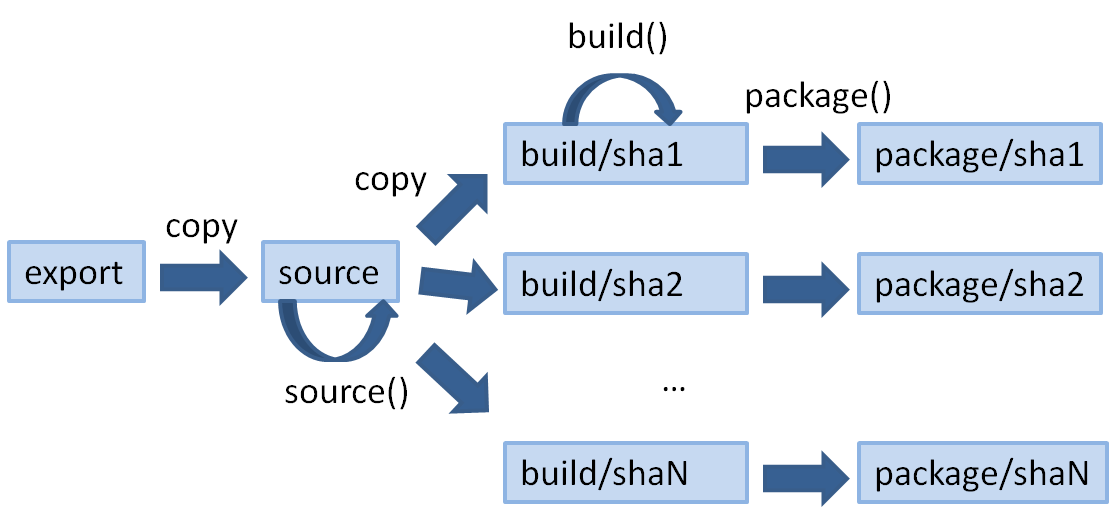
Each block in the diagram above is a folder for a given package. The package recipe is stored in the “export” folder, it is copied to the “source” folder so that the recipe source() method can fetch the package source code. Then, for each different configuration (different settings, such as different compiler versions or architecture), a new, clean build folder is used, the recipe build() method is triggered, and finally, the artifacts (typically the headers and the libraries) are extracted by the package() method to the final package folder. Each package is identified by a SHA-1 hash of the configuration values.
Single configuration packages
This is the most used approach in Conan, used thoroughly in the documentation, and in most packages in conan.io. With this approach, each package contains the artifacts for only one configuration. So if there is a package recipe that builds a “hello” library, there will be one package containing the release version of the hello.lib library and a different package containing a hello_d.lib debug version of that library. The name suffix is optional, the library could be named the same without any problems, but it is used here to make it more clear.
The typical recipe for it would be something like this (not a complete recipe):
class HelloConan(ConanFile):
settings = "os", "compiler", "build_type", "arch"
def build(self):
cmake = CMake(self.settings)
cmake.configure(self) # calls "cmake . -G ... "
cmake.build(self) # calls "cmake --build ."
def package_info(self):
self.cpp_info.libs = ["hello"]
It is very important to note that it is declaring the build_type as a setting. This means that a different package will be generated for each different value of such setting.
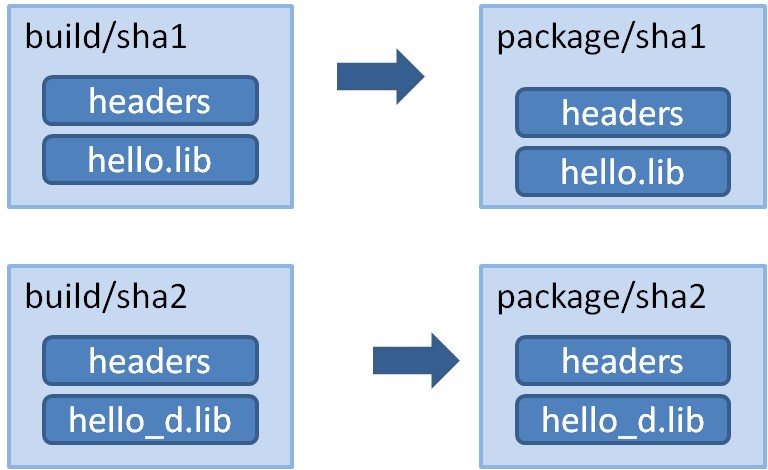
When installing these packages, the files generated for the build system, like the conanbuildinfo.cmake file by the cmake generator, will contain different information depending on the install settings:
set(CONAN_LIBS_HELLO hello)
...
set(CONAN_LIBS hello ${CONAN_LIBS})
If the developer wants to switch configuration of the dependencies, he will usually switch with:
$ conan install -s build_type=Release ...
// when need to debug
$ conan install -s build_type=Debug ...
These switches will be fast, since all the dependencies are already cached locally.
This process has some advantages: it is quite easy to implement and maintain. The packages are of minimal size, so disk space and transfers are faster, and builds from sources are also kept to the necessary minimum. The decoupling of configurations might help with isolating issues related to mixing different types of artifacts, and also protecting valuable information from deploy and distribution mistakes. For example, debug artifacts might contain symbols or source code, which could help or directly provide means for reverse engineering. So distributing debug artifacts by artifacts could be a very risky issue. The major disadvantage would be having to remember to install the specific configuration of dependencies while switching from Debug to Release and vice versa. This is something that heavy IDE users, such as Visual Studio, will find a bit inconvenient.
Consuming multiple debug/release single-configuration packages
Even if the packages are single-configuration, if the end-user developer want to use them easily in multi-configuration environments, like Visual Studio, they can do it via the CMake cmake_multi generator. With the generator, it’s enough to install both debug and release configurations of the dependencies:
$ conan install -g cmake_multi -s build_type=Release -s compiler.runtime=MD ...
$ conan install -g cmake_multi -s build_type=Debug -s compiler.runtime=MDd ...
These commands will generate 3 files: conanbuildinfo_multi.cmake, conanbuildinfo_debug.cmake and conanbuildinfo_release.cmake. The _debug and the _release files will contain their own cmake variables.
Then, use in the consumer CMakeLists.txt:
project(MyHello)
cmake_minimum_required(VERSION 2.8.12)
include(${CMAKE_BINARY_DIR}/conanbuildinfo_multi.cmake)
conan_basic_setup()
add_executable(say_hello main.cpp)
conan_target_link_libraries(say_hello)
Multi configuration packages
In multi-configuration packages, the same package will contain artifacts for different configurations. In our example, the same package could contain both the release and debug versions of the library “hello”.
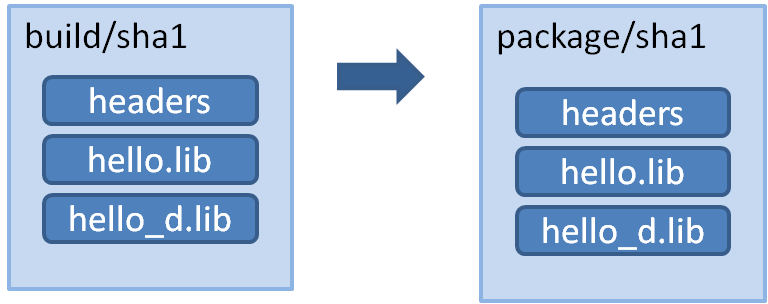
This doesn’t imply that you will only have 1 package or strictly 1 build folder per recipe, as you can still have different packages for different architectures, for example, or for different compiler versions. Package creators can define their unique packaging logic.
To implement this approach a package recipe could do:
def build(self):
cmake = CMake(self.settings)
if cmake.is_multi_configuration:
cmd = 'cmake "%s" %s' % (self.conanfile_directory, cmake.command_line)
self.run(cmd)
self.run("cmake --build . --config Debug")
self.run("cmake --build . --config Release")
else:
for config in ("Debug", "Release"):
self.output.info("Building %s" % config)
self.run('cmake "%s" %s -DCMAKE_BUILD_TYPE=%s'
% (self.conanfile_directory, cmake.command_line, config))
self.run("cmake --build .")
shutil.rmtree("CMakeFiles")
os.remove("CMakeCache.txt")
And assuming that a _d suffix name is being used (other approaches are valid, as having different folders), the package_info() method could be:
def package_info(self):
self.cpp_info.release.libs = ["hello"]
self.cpp_info.debug.libs = ["hello_d"]
These packages do not require specifying the build type at install time, and if provided, it will be ignored, for example, for consumers using the cmake generator:
$ conan install -g cmake # no -s build_type=Release/Debug
This will generate different variables for the consumer build system in the same conanbuildinfo.cmake, like:
set(CONAN_LIBS_HELLO_DEBUG hello_d)
set(CONAN_LIBS_HELLO_RELEASE hello)
...
set(CONAN_LIBS_DEBUG hello_d ${CONAN_LIBS_DEBUG})
set(CONAN_LIBS_RELEASE hello ${CONAN_LIBS_RELEASE})
This approach will have the risk of distribution of debug artifacts, as mentioned above, this is an important issue that could facilitate reverse engineering. Also, packages will always be larger, taking more time to build, to transfer and to install, even if you are not using all the artifacts (like in production). The major advantage is that it’s easier for developers to jump between debug and release configurations in their IDEs without having to do anything else.
Build once, package many
It’s possible that an already existing build script is building binaries for different configurations at once, like debug/release, or different architectures (32/64bits), or library types (shared/static). If such build script is used in the previous “Single configuration packages” approach, it will definitely work without problems, but we’ll be wasting precious build time, as we’ll be re-building the whole project for each package, then extracting the relevant artifacts for the given configuration, leaving the others.
With Conan 0.20, it is possible to specify the logic, so the same build can be reused to create different packages, which will be more efficient:
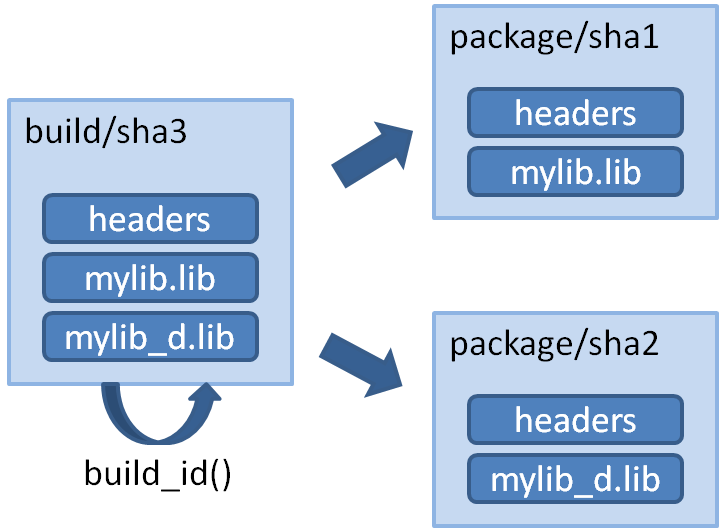
This can be done by defining a build_id() method in the package recipe that will specify the logic.
settings = "os", "compiler", "arch", "build_type"
def build_id(self):
self.info_build.settings.build_type = "Any"
def package(self):
if self.settings.build_type == "Debug":
#package debug artifacts
else:
# package release
Note that the build_id() method uses the self.info_build object to alter the build hash. If the method doesn’t change it, the hash will match the package folder one. By setting build_type="Any", we are forcing that for both Debug and Release values of build_type, the hash will be the same (the particular string is mostly irrelevant, as long as it is the same for both configurations). Note that the build hash sha3 will be different of both sha1 and sha2 package identifiers.
This doesn’t imply that there will be strictly one build folder. There will be a build folder for every configuration (architecture, compiler version, etc). So if we just have Debug/Release build types, and we’re producing N packages for N different configurations, we’ll have N/2 build folders, saving half of the build time.
Conclusion
This blog post illustrates how Conan allows for very different packaging paradigms. This is a constant effort that’s driven by our community of maintainers, contributors and users, who try to provide the tools to support the very different use-cases and needs that we have in our C and C++ communities. Many thanks to all of them!